from keras.models import Sequential
from keras.layers import Dense
import pandas as pd
from sklearn.model_selection import train_test_split
import os
os.chdir("데이터를 불러올 폴더경로")
os.getcwd() # 현재위치 확인
iris_data = pd.read_csv("iris.csv", encoding = 'utf-8', names=['a','b','c','d','y'])데이터를 불러와보자
y = iris_data.loc[:,'y']
x = iris_data.loc[:,["a","b","c","d"]]데이터와 레이블을 구분하였다.
from sklearn.preprocessing import LabelEncoder
from keras.utils import np_utils
e = LabelEncoder()
e.fit(y)
y1 = e.transform(y)

왼쪽의 문자로된 레이블을 오른쪽 숫자로 바꿔주는 작업이다. 아직 학습시키기위해서는 one-hot 인코딩이라는 작업이 남아있다.
y_encoded = np_utils.to_categorical(y1)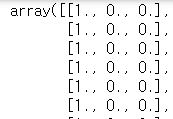
이렇게 데이터의 모양을 바꿔주면 학습이 가능해진다.
x_train, x_test, y_train, y_test = train_test_split(x,y_encoded, test_size=0.3,
train_size=0.7, shuffle=True)학습데이터와 테스트 데이터로 나누어보자.
model = Sequential()
model.add(Dense(128, input_dim=4, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(3, activation='softmax'))간단하게 모델을 만들어보자
여기서 input_dim은 학습할 데이터의 컬럼갯수라고 생각하면된다.(레이블열 제외)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])모델을 만들고 컴파일도 반드시 잊지말자.
model.fit(x_train, y_train, epochs = 200, batch_size=10)트레이닝데이터와 라벨을 넣고 학습을 시키자.

평가해보니 SVC모델을 썼을때보다 0.02가 올라갔다
'머신러닝 > 입문' 카테고리의 다른 글
| 랜덤포레스트에 대해 간단히 실습해보자 (0) | 2019.09.30 |
|---|---|
| SVC 서포트 벡터 머신에 대한 간단한 예제 (0) | 2019.09.30 |

